-
SQLD[요약정리(4)05/05~05/28]자격증/sqld 2022. 5. 13. 17:46
WHERE절 SQL>> SELECT 칼럼명 FROM 테이블명 WHERE 조건절;
2. 연산자 종류
- 비교 연산자: =, >, >=, <, <=
-비교 대상 데이터 타입에 따라 자동으로 형 변환되는 경우도 있음
-부정 비교 연산자: ‘NOT 칼럼명 비교연산자’와 동일
-부등호: !=, ^=, <> (ISO 표준)
- SQL 연산자 입력값을 비교하여 논리값 출력
- BETWEEN A AND B : A와 B 사잇값
-IN (리스트) : 리스트 내의 값
- LIKE ‘문자열’ : 문자열의 형태와 일치하는 값
※ 와일드카드: 1) ‘%’(퍼센트)는 0개 이상의 문자 2) ‘_’(언더바)는 1개의 단일 문자
- IS NULL : NULL은 등호로 판단 불가 어떤 상황에서도
- NOT BETWEEN A AND B, NOT IN (리스트), IS NOT NULL
- 논리 연산자: AND, OR, NOT
*우선순위: 부정 연산자 > 비교 연산자 > 논리 연산자
① ‘()’(괄호)
② NOT
③ 비교 연산자 및 SQL 연산자
④ AND
⑤ OR
* 문자열 비교방법
- CHAR vs CHAR : 첫 서로 다른 문자열 값으로 비교 (뒤 순서가 더 큰 값), 길이가 다를 때 공백을 추가하여 길이 맞춤 (공백 수만 다르면 같은 값)
-CHAR vs VARCHAR : 첫 서로 다른 문자열 값으로 비교, 길이가 다르면 길이가 긴 값이 크다고 판단, VARCHAR의 공백도 문자로 판단, TRIM 함수로 VARCHAR의 공백 제거하고 판단할 수 있음
- CHAR vs 상수 : 상수를 변수 타입으로 바꿔 비교
3. 부분 범위 처리
-ROWNUM (Oracle): SQL 처리 결과 집합의 각 행에 임시로 부여되는 번호, 조건절 내에서 행의 개수를 제한하는 목적으로 사용함
-TOP (SQL Server): 출력 행의 수 제한 함수, ’TOP (N)’로 N개 행 출력, 개수 대신 비율로도 제한 가능
※ ORDER BY절이 없으면 ROWNUM과 TOP의 기능이 같음
6절 함수
1. 단일 행 함수: 1) SELECT절 2) WHERE절 3) ORDER BY절에 사용 가능, 각 행에 개별적으로 작용, 여러 인자를 입력해도 단 하나의 결과만 출력
* 문자형 함수: 문자열 입력 시 문자열이나 숫자 반환
- LOWER, UPPER, LENGTH
- CONCAT : 문자열 결합
- SUBSTR : 문자열 부분 추출
- LTRIM, RTRIM, TRIM : 왼쪽 공백 제거, 오른쪽 공백 제거, 양쪽 공백 제거
- ASCII : 아스키 코드값 출력

* 숫자형 함수
- ABS, SIGN : 절대값, 부호 (1, 0, -1 중 출력)
- MOD : 나머지, 연산자 ’%’로 대체 가능함
- ROUND, CEIL, FLOOR : 반올림, 올림, 버림 (‘함수(E,N)’으로 소수점 이후 N번째 자리까지 출력)
- TRUNC : 숫자형 부분 추출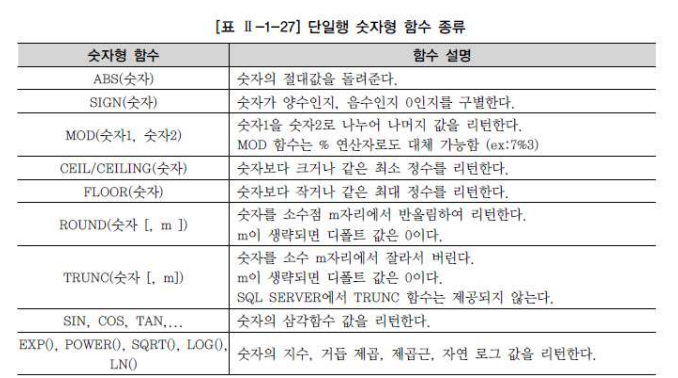

*날짜형 함수
- SYSDATE : 현재 시각 출력 (년, 월, 일, 시, 분, 초)
- EXTRACT : 날짜형 부분 추출 SQL>> SELECT EXTRACT(부분 FROM SYSDATE) FROM DUAL;
- ±숫자, ±숫자/24 : 일자 연산, 시간 연산
- NEXT_DAY : 지정된 요일 첫 날짜 출력
*변환형 함수: 데이터 타입 변환, 명시적 형 변환 방식
- TO_NUMBER, TO_CHAR, TO_DATE (Oracle): 문자열을 숫자로, 숫자나 날짜를 문자열로, 문자열을 날짜로
- CAST, CONVERT (SQL Server)
*NULL 관련 함수
- NVL(칼럼,값) : NULL 값 변환
- NVL2(칼럼,값,값) : NULL이면 앞의 값 아니면 뒤의 값 출력
- NULLIF(값,값) : 같으면 NULL 다르면 첫 값 출력
- COALESCE(값,값,…) : NULL이 아닌 첫 값 출력
- ISNULL(칼럼,값) : NULL이면 값으로 대치 아니면 칼럼 값 출력

2. 데이터 변환
-명시적 형 변환: 변환형 함수를 이용하여 데이터 타입 변환- 암시적 형 변환: DBMS가 자동으로 데이터 타입 변환
3. 조건문: IF-THEN-ELSE 형태
 CASE WHEN 조건절1 THEN 출력값1 … ELSE 기본값 END : ELSE 생략 시 NULL 출력
※ ‘CASE WHEN NULL THEN 출력값 ELSE 기본값’은 조건이 없으므로 모든 행에서 기본값 출력 (일반적으로 ‘WHEN 칼럼 IS NULL’로 수정 필요)
-DECODE (칼럼, 기준값1, 출력값1, …, 기본값) : Oracle 함수, 기준값n이면 출력값n 출력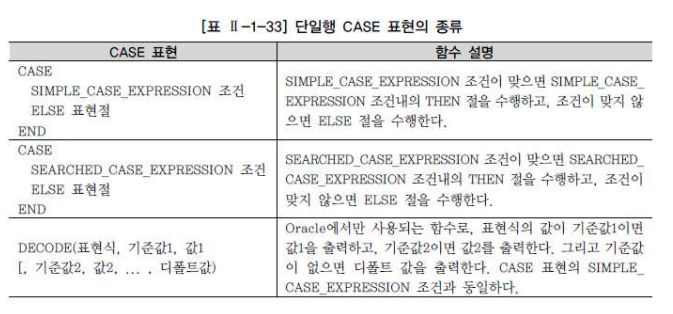
7절 GROUP BY, HAVING절
1. 집계 함수(Aggregate Function): 그룹별 결과 출력, 다중 행 함수 중 하나, GROUP BY절이 없으면 그룹핑 대상이 존재하지 않아 에러 발생, WHERE절에 사용 불가, 공집합에서도 연산 수행
* ALL, DISTINCT : 전체 출력, 중복 제외 출력
* SUM, AVG, MAX, MIN, VARIAN, STDDEV : NULL 제외하고 연산 (↔ 숫자 연산은 NULL 출력)
* COUNT : 행 수 출력
- COUNT(*) : NULL 포함
- COUNT(표현식) : NULL 제외
2. GROUP BY: 그룹핑 기준 설정, 앨리어스 사용 불가
3. HAVING: GROUP BY절에 의한 집계 데이터에 출력 조건을 걺 (↔ WHERE절은 SELECT절에 조건을 걸기 때문에 제외된 데이터가 GROUP BY 대상이 아님), 일반적으로 GROUP BY 뒤에 위치함
8절 ORDER BY절
1. ORDER BY: 특정 칼럼을 기준으로 정렬, 기본 정렬기준은 오름차순
* 1) 칼럼명 2) 앨리어스 3) 칼럼의 SELECT절에서 순서로 칼럼 지정 가능, SELECT절에 없는 칼럼도 지정 가능, GROUP BY절이 있으면 GROUP BY 대상 칼럼만 지정 가능
* Oracle은 NULL을 최대값으로 판단함 회장님은 상사가 없음 (↔ SQL Server은 최소값으로 판단함)
2. SELECT문 실행 순서
* 테이블에서 출력 대상이 아닌 것은 제거하고 그룹핑해서 그룹핑된 값이 조건에 맞는 데이터를 계산 및 출력하고 정렬함
SELECT 칼럼명 AS “별명” ⑤ 계산 및 출력하고
FROM 테이블명 ① 테이블에서
WHERE 조건식 ② 출력 대상이 아닌 것은 제거하고
GROUP BY 칼럼/표현식 ③ 그룹핑해서
HAVING 조건식 ④ 그룹핑된 값이 조건에 맞는 데이터를
ORDER BY 칼럼/표현식 ⑥ 정렬함
9절 조인
1. 조인: 여러 테이블을 연결 또는 결합하여 데이터를 출력하는 것, 일반적으로 PK나 FK의 연관성에 의해 성립
2. 등가 조인: 두 테이블의 칼럼 값이 정확히 일치하는 경우, 대부분 PK와 FK 관계를 기반으로 함
SQL>> SELECT 칼럼s FROM 테이블1 A, 테이블2 B WHERE A.칼럼명=B.칼럼명;
* SELECT 대상 칼럼이 두 테이블 모두에 있는 경우 앨리어스를 지정해야 함 (양쪽 앨리어스 모두 무관)
3. 비등가 조인: 두 테이블의 칼럼 값이 정확하게 일치하지 않는 경우, 부등호나 BETWEEN 연산자를 통해 조인
2장 SQL 활용
1절 표준조인
1. SQL에서의 연산
집합 연산
UNION
UNION
합집합
INTERSECTION
INTERSECT
교집합
DIFFERENCE
MINUS (오라클)
EXCEPT (SQL Server)
차집합
PRODUCT
CROSS JOIN
곱집합 (생길 수 있는 모든 데이터 조합)
관계 연산
SELECT
WHERE절
조건에 맞는 행 조회
PROJECT
SELECT절
조건에 맞는 칼럼 조회
JOIN
여러 JOIN
DIVIDE
없음
공통요소를 추출하고 분모 릴레이션의 속성을 삭제한 후 중복된 행 제거
2. ANSI/ISO SQL의 조인 형태: INNER JOIN, NATURAL JOIN, CROSS JOIN, OUTER JOIN
3. NATURAL JOIN: 같은 이름을 가진 칼럼 전체에 대한 등가 조인, USING 조건절이나 ON 조건절 사용 불가, 같은 데이터 유형 칼럼만 조인 가능, 앨리어스나 테이블명 사용 불가
SQL>> SELECT 칼럼s FROM 테이블1 NATURAL JOIN 테이블2;
4. INNER JOIN: 행에 동일한 값이 있는 칼럼 조인, JOIN의 디폴트 옵션, USING 조건절이나 ON 조건절 필수, CROSS JOIN이나 OUTER JOIN과 동시 사용 불가, 두 테이블에 동일 이름 칼럼이 있을 경우 SELECT절에 앨리어스 필수
SQL>> SELECT 칼럼s FROM 테이블1 A, 테이블2 B WHERE A.칼럼=B.칼럼;
SQL>> SELECT 칼럼s FROM 테이블1 A INNER JOIN 테이블2 B ON A.칼럼=B.칼럼; (ANSI/ISO 표준)
* USING 조건절: 같은 이름을 가진 칼럼 중 등가 조인 대상 칼럼 선택, SQL Server에서는 지원하지 않음, 조건절에 앨리어스나 테이블명 불가
SQL>> SELECT 칼럼s FROM 테이블1 A JOIN 테이블2 B USING (칼럼명);
* ON 조건절: 다른 이름을 가진 칼럼 간 조인 가능 (앨리어스나 테이블명 필수), 괄호는 의무사항 아님
SQL>> SELECT 칼럼s FROM 테이블1 A JOIN 테이블2 B ON (A.칼럼=B.칼럼);
5. CROSS JOIN: 가능한 모든 조합으로 조인
SQL>> SELECT 칼럼 FROM 테이블1, 테이블2; (조인 조건이 없을 때 발생 ↔ NATURAL JOIN은 명시해야 됨)
6. OUTER JOIN: 조인 조건에서 행에 동일한 값이 없는 칼럼 조인, USING 조건절이나 ON 조건절 필수
* LEFT OUTER JOIN: 좌측 테이블 데이터 조회 후 우측 테이블 조인 대상 데이터 조회
SQL>> SELECT 칼럼s FROM 테이블1 A, 테이블2 B A.칼럼=B.칼럼(+);
SQL>> SELECT 칼럼s FROM 테이블1 A
ㅇ LEFT OUTER JOIN 테이블2 B
ㅇ ON (A.칼럼=B.칼럼);
* RIGHT OUTER JOIN 오른쪽 결과가 더 긺
* FULL OUTER JOIN: LEFT와 RIGHT OUTER JOIN 포함
SQL>> SELECT 칼럼s FROM 테이블1 A 결과:
ㅇ FULL OUTER JOIN 테이블2 B
ㅇ ON (A.칼럼=B.칼럼);
2절 집합 연산자
1. 집합 연산자: 조인 없이 여러 테이블의 관련 데이터를 조회하는 연산자
2. UNION: 합집합, 칼럼 수와 데이터 타입이 모두 동일한 테이블 간 연산만 가능
SQL>> SELECT 칼럼명 FROM 테이블명 A WHERE 조건절 UNION SELECT 테이블명 WHERE 조건절;
* UNION ALL: 중복된 행도 전부 출력하는 합집합, 정렬 안함 (↔ UNION은 정렬을 유발함), 집합 연산자에 속함
SQL>> SELECT 칼럼명 FROM 테이블명 A WHERE 조건절 UNION ALL SELECT 테이블명 WHERE 조건절;
3. INTERSECT: 교집합
SQL>> SELECT 칼럼명 FROM 테이블명 A WHERE 조건절MS INTERSECT SELECT 테이블명 WHERE 조건절;
4. MINUS, EXCEPT: 차집합
SQL>> SELECT 칼럼명 FROM 테이블명 A WHERE 조건절 MINUS SELECT 테이블명 WHERE 조건절;
3절 계층형 질의와 셀프 조인
1. 계층형 질의(Hierarchical Query): 계층형 데이터를 조회하기 위해 사용함, Oracle에서 지원함
* 계층형 데이터: 엔터티를 순환관계 데이터 모델로 설계할 때 발생함
* CONNECT BY : 트리 형태의 구조로 쿼리 수행 (루트 노드부터 하위 노드의 쿼리를 실행함) 상사 이름과 사람 이름을 조인하여 상사 밑에 넣기
- START WITH : 시작 조건 지정
- CONNECT BY PRIOR : 조인 조건 지정
LEVEL : 검색 항목의 깊이, 최상위 계층의 레벨은 1
CONNECT_BY_ROOT : 최상위 계층 값 표시
CONNECT_BY_ISLEAF : 최하위 계층 값 표시
SYS_CONNECT_BY_PATH : 계층 구조의 전개 경로 표시
- CONNECT BY절의 루프 알고리즘 키워드
NOCYCLE : 순환구조의 발생지점까지만 전개
CONNECT_BY_ISCYCLE : 순환구조 발생지점 표시 (부모 노드와 자식 노드가 같을 때 1 아니면 0 출력)
* LPAD : 계층형 조회 결과를 명확히 하기 위해 사용 (LEVEL 값을 이용하여 결과 데이터 정렬)
2. SQL Server 계층형 질의: CTE(Common Table Expression)로 재귀 호출
3. 셀프 조인: 한 테이블 내에서 두 칼럼이 연관 관계가 있는 경우, 앨리어스 필수
4절 서브쿼리
1. 서브쿼리: 하나의 SQL문 안의 SQL문
2. 종류
* 동작 방식에 따른 분류
- 비연관 서브쿼리: 메인쿼리 칼럼을 가지고 있지 않는 서브쿼리, 메인쿼리에 값을 제공하기 위한 목적으로 주로 사용함
Access Subquery: 제공자 역할
Filter Subquery: 확인자 역할
Early Filter Subquery: 데이터 필터링 역할
- 연관 서브쿼리(Associative Subquery): 메인쿼리의 결과를 조건이 맞는지 확인하기 위한 목적으로 주로 사용함
* 반환 데이터 형태에 따른 분류
- 단일 행 서브쿼리: 실행 결과가 1건 이하인 서브쿼리, 단일 행 비교 연산자와 함께 사용
- 다중 행 서브쿼리: 실행 결과가 여러 건인 서브쿼리, 다중 행 비교 연산자와 함께 사용
※ 다중 행 비교 연산자
" IN : 서브쿼리의 결과 중 하나의 값이라도 동일하다는 조건
" ANY : 서브쿼리의 결과 중 하나의 값이라도 만족한다는 조건
" ALL : 서브쿼리의 모든 결과값을 만족한다는 조건
" EXISTS : 서브쿼리의 결과를 만족하는 값이 존재하는지 여부를 확인하는 조건, ‘WHERE EXISTS (SELECT ~)’ (항상 연관 서브쿼리로 사용)
- 다중 칼럼 서브쿼리: 실행 결과로 여러 칼럼 반환, 주로 메인쿼리의 조건과 비교하기 위해 사용 (비교하고자 하는 칼럼의 개수와 위치가 동일해야 함)
3. 스칼라 서브쿼리: 값 하나를 반환하는 서브쿼리, SELECT절에 사용하는 서브쿼리
4. 뷰: 가상의 테이블, FROM절에 사용하는 뷰는 인라인 뷰(Inline View)라고 함
* 장점
- 독립성: 테이블 구조 변경 자동 반영
- 편리성: 쿼리를 단순하게 작성할 수 있음, 자주 사용하는 SQL문의 형태를 뷰로 생성하여 사용할 수 있음
- 보안성: 뷰를 생성할 때 칼럼을 제외할 수 있음
5. WITH: 서브쿼리를 이용하여 뷰로 사용할 수 있는 구문
SQL>> WITH 뷰명 AS (SELECT ~)
5절 그룹 함수
1. ANSI/ISO 표준 데이터 분석 함수: 집계 함수, 그룹 함수, 윈도우 함수
2. 그룹 함수(Group Function): 합계 계산 함수, NULL을 빼고 집계함 (~ 집계 함수), 결과값 없는 행은 출력 안함
* ROLLUP : GROUP BY로 묶인 칼럼의 소계 계산, 계층 구조로 GROUP BY의 칼럼 순서가 바뀌면 결과 값 바뀜
* CUBE : 조합 가능한 모든 값에 대해 다차원 집계
* GROUPING SETS : 특정 항목에 대한 소계 계산, GROUP BY의 칼럼 순서와 무관하게 개별적으로 처리함
표현식
출력값
GROUP BY ROLLUP (E1,E2)
E1과 E2별 소계 / E1별 소계 / 총합계
GROUP BY CUBE (E1,E2)
E1과 E2별 소계 / E1별 소계 / E2별 소계 / 총합계
GROUP BY GROUPING SETS (E1,E2)
E1별 소계 / E2별 소계
※ ‘GROUP BY CUBE (E1,E2)’와 ‘GROUP BY GROUPING SETS (E1,E2,(E1,E2),())’는 동일한 결과 출력
3. GROUPING : 그룹 함수에서 생성되는 합계를 구분해주는 함수, 소계나 합계가 계산되면 1 아니면 0 반환
6절 윈도우 함수
1. 윈도우 함수(Window Function): 여러 행 간의 관계 정의 함수, 중첩 불가
* 순위 함수
- RANK : 중복 순위 포함
- DENSE_RANK : 중복 순위 무시 (중간 순위를 비우지 않음)
- ROW_NUMBER : 단순히 행 번호 표시, 값에 무관하게 고유한 순위 부여
* 일반집계 함수: SUM, MAX, MIN, AVG, COUNT
* 행 순서 함수
- FIRST_VALUE, LAST_VALUE : 첫 값, 끝 값
- LAG, LEAD : 이전 행, 이후 행 (Oracle) 랙릿
※ ‘LEAD(E,A)’는 E에서 A번째 행의 값을 호출하는 형태로도 쓰임 (A의 기본값은 1)
* 비율 관련 함수
- PERCENT_RANK() : 백분율 순서
- CUME_DIST() : 현재 행 이하 값을 포함한 누적 백분율
- NTILE(A) : 전체 데이터 A등분
- RATIO_TO_REPORT : 총합계에 대한 값의 백분율
2. 윈도우 함수 문법
SQL>> SELECT 윈도우함수(A) OVER (PARTITION BY 칼럼 ORDER BY 칼럼 윈도잉절) FROM 테이블명;
* PARTITION BY : 그룹핑 기준
* ORDER BY : 순위 지정 기준
* 윈도잉절 : 함수의 대상이 되는 행 범위 지정
- BETWEEN A AND B : 구간 지정
N PRECEDING, N FOLLOWING : N번째 앞 행, N번째 뒤 행
UNBOUNDED PRECEDING, UNBOUNDED FOLLOWING : 첫 행, 끝 행
CURRENT ROW : 현재 행
- ROWS, RANGE : 행 지정, 값의 범위 지정
7절 DCL
1. DCL: 유저를 생성하거나 권한을 제어하는 명령어, 보안을 위해 필요함
* GRANT: 권한 부여
SQL>> GRANT 권한 ON 오브젝트 TO 유저명;
* REVOKE: 권한 제거
SQL>> REVOKE 권한 ON 오브젝트 TO 유저명;
2. 권한(Privileges)
* SELECT, INSERT, UPDATE, DELETE, ALTER, ALL : DML 관련 권한
* REFERENCES : 지정된 테이블을 참조하는 제약조건을 생성하는 권한
* INDEX : 지정된 테이블에서 인덱스를 생성하는 권한
3. Oracle의 유저
* SCOTT: 테스트용 샘플 유저
* SYS: DBA 권한이 부여된 최상위 유저
* SYSTEM: DB의 모든 시스템 권한이 부여된 DBA
4. ROLE: 권한의 집합, 권한을 일일이 부여하지 않고 ROLE로 편리하게 여러 권한을 부여할 수 있음
* Oracle의 ROLE
ROLE
권한
CONNECT
CREATE SESSION
RESOURCE
CREATE CLUSTER
CREATE PROCEDURE
CREATE TYPE
CREATE SEQUENCE
CREATE TRIGGER
CREATE OPERATOR
CREATE TABLE
CREATE INDEXTYPE
8절 절차형 SQL
1. 절차형 SQL: 일반적인 개발언어처럼 절차지향적인 프로그램을 작성할 수 있도록 제공하는 기능
* SQL문의 연속적인 실행 및 조건에 따른 분기처리를 이용하여 특정 기능을 수행하는 저장 모듈 생성 가능
* PL/SQL (Oracle)
- 블록 구조: 블록 내에 1) DML 2) 쿼리 3) IF나 LOOP 등을 사용할 수 있음
Declare(선언부): 블록에서 사용할 변수나 인수에 대한 정의
Begin(실행부): 처리할 SQL문 정의
Exception(예외 처리부): 블록에서 발생한 에러 처리 로직 정의, 유일한 선택 항목
* T-SQL (SQL Server)
2. 프로시저(Procedure)
3. 사용자 정의 함수: 절차형 SQL을 로직과 함께 DB 내에 저장해 놓은 명령문 집합, RETURN을 통해 반드시 하나의 값 반환 (↔ 프로시저)
4. 트리거(Trigger): DML문이 수행되었을 때 자동으로 동작하는 프로그램 (↔ 프로시저는 EXECUTE로 실행함), DCL와 TCL 실행 불가 (↔ 프로시저는 사용 가능함)
3장 SQL 최적화 기본 원리
1절 옵티마이저와 실행계획
1. 옵티마이저: SQL문에 대한 최적의 실행방법을 결정하여 실행 계획 도출, SQL문에 대한 파싱 후 실행됨, 내비게이션
※ SQL문 실행 순서
① 파싱(Parsing): SQL 문법 검사 및 구문 분석 작업
② 실행(Execution): 옵티마이저의 실행 계획에 따라
③ 인출(Fetch): 데이터를 읽어 전송
* 옵티마이저 엔진
- 질의 변환기(Query Transformer): 작성된 SQL문을 처리하기 용이한 형태로 변환하는 모듈
- 비용 예측기(Estimator): 생성된 계획의 비용을 예측하는 모듈
- 대안계획 생성기(Plan Generator): 동일한 결과를 생성하는 다양한 대안 계획을 생성하는 모듈, 1) 연산 적용 순서 2) 연산 방법 3) 조인 순서의 변경을 통해 대안 계획 생성
* 종류
- 규칙기반 옵티마이저: 우선순위 규칙에 따라 실행계획 생성, 인덱스가 있으면 반드시 인덱스 사용
- 비용기반 옵티마이저: 처리 비용이 가장 적은 실행계획 선택, 데이터 딕셔너리(Data Dictionary)의 통계정보나 DBMS의 차이로 같은 쿼리도 다른 실행계획이 생성될 수 있음, 실행계획의 예측 및 제어가 어려움
2. SQL 처리 흐름도: SQL문의 처리절차를 시각적으로 표현한 도표
3. 실행계획: 1) 객체 2) 조인 방법 및 순서 3) 액세스 패턴 등의 정보 출력
* DESC PLAN_TABLE; : 실행 계획 확인
* 해독 순서: ←로 찾다가 2줄 이상의 동일 레벨을 만나면 ↓로 해독
2절 인덱스 기본
1. 인덱스: 검색 조건에 부합하는 데이터를 효과적으로 검색할 수 있도록 돕는 기능, 인덱스키로 정렬되어 있어 조회 속도가 빠름, DML 작업 효율은 저하함
* 트리기반 인덱스: DBMS에서 사용하는 가장 일반적인 인덱스, 1) 루트 블록(Root Block) 2) 브랜치 블록(Branch Block) 3) 리프 블록(Leaf Block)으로 구성됨
- 포인터(Pointer): 루트 블록과 브랜치 블록의 키 값, 하위 블록 키 값의 범위 정보
- 리프 블록은 1) 인덱스키 2) ROWID로 구성됨, Doubly Linked List 형태라서 양방향 탐색 가능
※ ROWID: Oracle에서 데이터를 구분할 수 있는 유일한 값, 데이터를 입력하면 자동으로 생성됨, 데이터가 어떤 데이터 파일의 어느 블록에 속해 있는지 알려줌
" 오브젝트 번호: 해당 데이터가 속하는 오브젝트 번호, 오브젝트 별로 유일한 값을 가짐
" 상대 파일 번호: 테이블스페이스 내 데이터 파일의 순번
" 블록 번호: 데이터 파일 내 데이터가 속해 있는 블록의 순번
" 데이터 번호: 데이터 블록에 데이터가 저장되어 있는 순번
* 클러스터형 인덱스 (SQL Server): 인덱스의 리프 페이지가 데이터를 포함함, 리프 페이지의 모든 로우가 인덱스키 칼럼 순서대로 물리적으로 정렬되어 있음
* CREATE INDEX 인덱스명 테이블명 ON 테이블명 (칼럼명, …) : 인덱스 생성
※ 인덱스키가 변환되면 사용 불가 ex) NVL(인덱스키,값), TO_타입(인덱스키), 인덱스키||값
2. 인덱스 스캔 효율화: 랜덤 액세스 최소화 (인덱스 스캔 후 추가 정보를 가져오기 위한 랜덤 액세스는 DBMS 성능 부하를 유발함)
※ 인덱스 칼럼의 순서는 랜덤 액세스와 무관함
3. 스캔 방법
* 전체 테이블 스캔(Full Table Scan): 테이블의 모든 데이터를 읽으며 데이터 추출, 읽은 블록의 재사용성을 낮다고 판단하여 메모리 버퍼에서 제거함, 1) SQL문에 조건이 없거나 2) SQL문 조건 관련 인덱스가 없거나 3) 전체 테이블 스캔을 하도록 강제로 힌트를 지정하거나 4) 옵티마이저가 유리하다고 판단하는 경우 수행, 많은 데이터를 조회할 때 유리함
* 인덱스 스캔(Index Scan): 인덱스를 구성하는 칼럼의 값을 기반으로 데이터 추출, 인덱스를 읽어 ROWID를 찾고 해당 데이터를 찾기 위해 테이블을 읽음, 일반적으로 인덱스 칼럼 순서로 정렬되어 출력됨, 적은 데이터를 조회할 때 유리함, 1) 랜덤 액세스에 의한 부하가 발생할 수 있고 2) 중복 스캔 비효율이 발생함
- 인덱스 범위 스캔(Index Range Scan): 특정 범위에 인덱스 스캔 적용
인덱스 역순 범위 스캔: 리프 블록의 Doubly Linked List 저장 방식을 활용하여 인덱스를 역순으로 스캔, 결과 집합이 내림차순으로 정렬됨
- 인덱스 유일 스캔(Index Unique Scan): 인덱스키가 중복되지 않을 때 단 한 건의 데이터 추출, 등호 조건으로 조회함, 검색 속도가 가장 빠름
- 인덱스 전체 스캔(Index Full Scan): 리프 블록을 모두 읽으며 데이터 추출
인덱스 고속 전체 스캔: 물리적으로 저장된 순서대로 인덱스 리프 블록 스캔
인덱스 스킵 스캔: 인덱스 선두 칼럼이 조건절에 없어도 활용함, 상위 블록에서 읽은 칼럼 값 정보를 이용해 조건에 맞는 데이터를 포함할 가능성이 있는 리프 블록만 접근
4. IOT(Index-Organized Table): 인덱스키가 붙은 칼럼으로 구성된 테이블, 인덱스가 원래 테이블을 참조하지 않음, 클러스터형 인덱스와 유사함
3절 조인 수행 원리
1. 조인 순서: 항상 두 테이블을 조인함
* 선행 테이블(First Table, Outer Table, Driving Table, Build Input)
* 후행 테이블(Second Table, Inner Table, Driven Table, Probe Input): 선행 테이블로부터 입력값을 받아 처리함, 후행 테이블에 걸리는 조인 조건이 성능에 큰 영향을 미침
2. 조인 방식: NL 조인 > 소트 머지 조인 > 해시 조인 순서로 발전됨
* NL 조인(Nested Loop Join): 선행 테이블의 데이터 하나씩 순차적으로 조인 (중첩 반복문과 유사함), 선행 테이블 처리 범위가 성능을 결정함 (~ 해시 조인, ↔ 소트 머지 조인은 순서에 무관함), 랜덤 액세스 위주이므로 대용량 데이터 처리 시 불리 유니크 인덱스를 이용하여 소량 테이블 조인할 때 유리함
- 절차
① 선행 테이블에서 조건을 만족하는 행을 찾음
② 후행 테이블에 선행 테이블의 조인키가 존재하는지 확인함
③ 후행 테이블 인덱스에 선행 테이블의 조인키가 존재하는지 확인함
④ 인덱스에서 추출한 ROWID로 후행 테이블을 액세스함
- 조인 결과를 하나씩 바로 출력하여 OLTP 환경에 적합함
* 소트 머지 조인(Sort Merge Join): 두 테이블을 개별적으로 스캔한 후 조인 (↔ NL 조인은 선행 테이블을 랜덤 액세스 방식으로 조회하며 조인), 대용량 데이터 처리 시 디스크에서 정렬이 진행되므로 성능상 불리, 인덱스 유무가 성능에 큰 영향을 주지 않음 (↔ NL 조인은 인덱스 구성에 크게 영향을 받음)
* 해시 조인(Hash Join): 조인 칼럼을 기준으로 동일한 해시 값을 갖는 데이터의 실제 값을 비교하며 조인, 두 테이블의 데이터 차이가 클 때 유리, 1) NL 조인의 랜덤 액세스와 2) 소트 머지 조인의 정렬 작업 부담 해결, 등가 조인에서만 사용할 수 있음, 해시 메모리에서 해시 테이블을 생성하므로 선행 테이블이 작을 때 유리 테이블이 커서 소트 부하가 심할 때 유리함
- OLAP 환경에 적합함'자격증 > sqld' 카테고리의 다른 글
sqld 30회 기출 오답정리(1) (0) 2022.05.18 sqld[빈출 개념 복습05/05~05/28] (0) 2022.05.17 SQLD[요약정리(3)05/05~05/28] (0) 2022.05.10 SQLD[요약정리(2)05/05~05/28] (0) 2022.05.09 SQLD[요약정리05/05~05/28] (0) 2022.05.05